Przeszukaj forum
Pokazywanie wyników dla tagów 'vhdl'.
Znaleziono 4 wyniki
-
 Cześć, postanowiłem dzisiaj wypróbować generację kodu VHDL z użyciem "chat GPT". Założenia były takie, że mamy tablicę (bufor obrazu) o rozdzielczości VGA (640x480 pikseli, gdzie kazdy piksel ma 16 bitów). Aby kod był niezależny od konkretnej kości FPGA załozyłem, że opis obrazu jest w tablicy języka VHDL: signal image : array(0 to 639, 0 to 479) of STD_LOGIC_VECTOR(15 downto 0); a obraz wyjściowy (krawędzie) są w tablicy: signal edge_buffer : array(0 to 639, 0 to 479) of STD_LOGIC; Jest to po to aby abstrahować od konkretnego miejsca przechowywania obrazu (bufor obrazu), który docelowo może być w pamięci BLOCK_RAM układu FPGA lub w zewnętrznej pamięci RAM. Na początku poprosiłem "chatGPT" o wygenerowanie prostego przykładu filtrowania obrazu filtrem Sobel'a. Kod został szybko wygenerowany i wydawał się być całkiem poprawny (porównałem podstawową implementację filtru Sobel'a w języku C++). Nastepnie prosiłem chatGPT o dodawanie kolejnych opcji zrównoleglania - po kolei: 1) Zrównoleglanie liczby jednocześnie przetwarzanych pikseli - stała: constant PARALLELISM : natural := 4; 2) Podział obrazu FPGA na bloki przetwarzane równolegle: constant NUM_BLOCKS_X : integer := 160; -- Ilość bloków pikseli w poziomie constant NUM_BLOCKS_Y : integer := 120; -- Ilość bloków pikseli w pionie 3) Dodanie pipeline do przetwarzania Tutaj cały wygenerowany kod VHDL: library IEEE; use IEEE.STD_LOGIC_1164.ALL; use IEEE.STD_LOGIC_ARITH.ALL; use IEEE.STD_LOGIC_UNSIGNED.ALL; entity SobelEdgeDetection is Port ( clk : in STD_LOGIC; reset : in STD_LOGIC; pixel_in : in STD_LOGIC_VECTOR(15 downto 0); edge_out : out STD_LOGIC ); end SobelEdgeDetection; architecture ParallelPipelinedBehavior of SobelEdgeDetection is type PixelBlock is array(0 to 3, 0 to 3) of STD_LOGIC_VECTOR(15 downto 0); signal block_x : integer := 0; signal block_y : integer := 0; signal image : array(0 to 639, 0 to 479) of STD_LOGIC_VECTOR(15 downto 0); signal edge_buffer : array(0 to 639, 0 to 479) of STD_LOGIC; signal sobel_x : integer; signal sobel_y : integer; signal gradient : integer; signal gradient_reg : integer := 0; constant sobel_mask_x : array(0 to 2, 0 to 2) of integer := ((-1, 0, 1), (-2, 0, 2), (-1, 0, 1)); constant sobel_mask_y : array(0 to 2, 0 to 2) of integer := ((-1, -2, -1), ( 0, 0, 0), ( 1, 2, 1)); constant NUM_BLOCKS_X : integer := 160; -- Ilość bloków pikseli w poziomie constant NUM_BLOCKS_Y : integer := 120; -- Ilość bloków pikseli w pionie constant PARALLELISM : natural := 4; signal processing_stage : integer := 0; signal sobel_x_stage : integer; signal sobel_y_stage : integer; signal gradient_stage : integer; signal edge_stage : STD_LOGIC; signal pipeline_ready : boolean := false; begin process(clk) begin if rising_edge(clk) then if reset = '1' then block_x <= 0; block_y <= 0; processing_stage <= 0; for i in 0 to 639 loop for j in 0 to 479 loop image(i, j) <= (others => '0'); edge_buffer(i, j) <= '0'; end loop; end loop; else -- Przetwarzanie równoległe z pipeliningiem if not pipeline_ready then case processing_stage is when 0 => -- Wczytywanie bloku pikseli for i in 0 to 3 loop for j in 0 to 3 loop image(block_x * 4 + i, block_y * 4 + j) <= pixel_in; end loop; end loop; if block_x = NUM_BLOCKS_X - 1 and block_y = NUM_BLOCKS_Y - 1 then pipeline_ready <= true; processing_stage <= 0; -- Reset etapu przetwarzania elsif block_x = NUM_BLOCKS_X - 1 then block_x <= 0; block_y <= block_y + 1; else block_x <= block_x + 1; end if; when 1 => -- Obliczenia gradientów sobel_x_stage <= (to_integer(unsigned(image(block_x * 4 - 1, block_y * 4 - 1))) * sobel_mask_x(0, 0)) + (to_integer(unsigned(image(block_x * 4, block_y * 4 - 1))) * sobel_mask_x(0, 1)) + (to_integer(unsigned(image(block_x * 4 + 1, block_y * 4 - 1))) * sobel_mask_x(0, 2)) + (to_integer(unsigned(image(block_x * 4 - 1, block_y * 4))) * sobel_mask_x(1, 0)) + (to_integer(unsigned(image(block_x * 4 + 1, block_y * 4))) * sobel_mask_x(1, 2)) + (to_integer(unsigned(image(block_x * 4 - 1, block_y * 4 + 1))) * sobel_mask_x(2, 0)) + (to_integer(unsigned(image(block_x * 4, block_y * 4 + 1))) * sobel_mask_x(2, 1)) + (to_integer(unsigned(image(block_x * 4 + 1, block_y * 4 + 1))) * sobel_mask_x(2, 2)); sobel_y_stage <= (to_integer(unsigned(image(block_x * 4 - 1, block_y * 4 - 1))) * sobel_mask_y(0, 0)) + (to_integer(unsigned(image(block_x * 4, block_y * 4 - 1))) * sobel_mask_y(0, 1)) + (to_integer(unsigned(image(block_x * 4 + 1, block_y * 4 - 1))) * sobel_mask_y(0, 2)) + (to_integer(unsigned(image(block_x * 4 - 1, block_y * 4))) * sobel_mask_y(1, 0)) + (to_integer(unsigned(image(block_x * 4 + 1, block_y * 4))) * sobel_mask_y(1, 2)) + (to_integer(unsigned(image(block_x * 4 - 1, block_y * 4 + 1))) * sobel_mask_y(2, 0)) + (to_integer(unsigned(image(block_x * 4, block_y * 4 + 1))) * sobel_mask_y(2, 1)) + (to_integer(unsigned(image(block_x * 4 + 1, block_y * 4 + 1))) * sobel_mask_y(2, 2)); gradient_stage <= abs(sobel_x_stage) + abs(sobel_y_stage); if gradient_stage > 1000 then edge_stage <= '1'; else edge_stage <= '0'; end if; processing_stage <= 2; -- Przejdź do etapu 2 when 2 => -- Wczytywanie wyników do bufora krawędzi edge_buffer(block_x * 4 + 3, block_y * 4 + 3) <= edge_stage; if block_x = NUM_BLOCKS_X - 1 and block_y = NUM_BLOCKS_Y - 1 then pipeline_ready <= false; -- Zakończenie przetwarzania bloku elsif block_x = NUM_BLOCKS_X - 1 then block_x <= 0; block_y <= block_y + 1; else block_x <= block_x + 1; end if; end case; end if; end if; end if; end process; end ParallelPipelinedBehavior; Co sądzicie o wygenerowanym kodzie - wstepnie go przeanalizowałem i na rzaie nie mogę znaleźć błędu. Co sądzicie ogólnie o generacji kodu w róznych językach programowania za pomocą "chatGPT" i ogólnie AI. Tutaj link do dużo potężniejszego narzędzia AI o nazwie kodowej "Gorilla" : https://lablab.ai/tech/gorilla Projekt "Gorilla" można za darmo testować na "Google Clolab". Pozdrawiam
Cześć, postanowiłem dzisiaj wypróbować generację kodu VHDL z użyciem "chat GPT". Założenia były takie, że mamy tablicę (bufor obrazu) o rozdzielczości VGA (640x480 pikseli, gdzie kazdy piksel ma 16 bitów). Aby kod był niezależny od konkretnej kości FPGA załozyłem, że opis obrazu jest w tablicy języka VHDL: signal image : array(0 to 639, 0 to 479) of STD_LOGIC_VECTOR(15 downto 0); a obraz wyjściowy (krawędzie) są w tablicy: signal edge_buffer : array(0 to 639, 0 to 479) of STD_LOGIC; Jest to po to aby abstrahować od konkretnego miejsca przechowywania obrazu (bufor obrazu), który docelowo może być w pamięci BLOCK_RAM układu FPGA lub w zewnętrznej pamięci RAM. Na początku poprosiłem "chatGPT" o wygenerowanie prostego przykładu filtrowania obrazu filtrem Sobel'a. Kod został szybko wygenerowany i wydawał się być całkiem poprawny (porównałem podstawową implementację filtru Sobel'a w języku C++). Nastepnie prosiłem chatGPT o dodawanie kolejnych opcji zrównoleglania - po kolei: 1) Zrównoleglanie liczby jednocześnie przetwarzanych pikseli - stała: constant PARALLELISM : natural := 4; 2) Podział obrazu FPGA na bloki przetwarzane równolegle: constant NUM_BLOCKS_X : integer := 160; -- Ilość bloków pikseli w poziomie constant NUM_BLOCKS_Y : integer := 120; -- Ilość bloków pikseli w pionie 3) Dodanie pipeline do przetwarzania Tutaj cały wygenerowany kod VHDL: library IEEE; use IEEE.STD_LOGIC_1164.ALL; use IEEE.STD_LOGIC_ARITH.ALL; use IEEE.STD_LOGIC_UNSIGNED.ALL; entity SobelEdgeDetection is Port ( clk : in STD_LOGIC; reset : in STD_LOGIC; pixel_in : in STD_LOGIC_VECTOR(15 downto 0); edge_out : out STD_LOGIC ); end SobelEdgeDetection; architecture ParallelPipelinedBehavior of SobelEdgeDetection is type PixelBlock is array(0 to 3, 0 to 3) of STD_LOGIC_VECTOR(15 downto 0); signal block_x : integer := 0; signal block_y : integer := 0; signal image : array(0 to 639, 0 to 479) of STD_LOGIC_VECTOR(15 downto 0); signal edge_buffer : array(0 to 639, 0 to 479) of STD_LOGIC; signal sobel_x : integer; signal sobel_y : integer; signal gradient : integer; signal gradient_reg : integer := 0; constant sobel_mask_x : array(0 to 2, 0 to 2) of integer := ((-1, 0, 1), (-2, 0, 2), (-1, 0, 1)); constant sobel_mask_y : array(0 to 2, 0 to 2) of integer := ((-1, -2, -1), ( 0, 0, 0), ( 1, 2, 1)); constant NUM_BLOCKS_X : integer := 160; -- Ilość bloków pikseli w poziomie constant NUM_BLOCKS_Y : integer := 120; -- Ilość bloków pikseli w pionie constant PARALLELISM : natural := 4; signal processing_stage : integer := 0; signal sobel_x_stage : integer; signal sobel_y_stage : integer; signal gradient_stage : integer; signal edge_stage : STD_LOGIC; signal pipeline_ready : boolean := false; begin process(clk) begin if rising_edge(clk) then if reset = '1' then block_x <= 0; block_y <= 0; processing_stage <= 0; for i in 0 to 639 loop for j in 0 to 479 loop image(i, j) <= (others => '0'); edge_buffer(i, j) <= '0'; end loop; end loop; else -- Przetwarzanie równoległe z pipeliningiem if not pipeline_ready then case processing_stage is when 0 => -- Wczytywanie bloku pikseli for i in 0 to 3 loop for j in 0 to 3 loop image(block_x * 4 + i, block_y * 4 + j) <= pixel_in; end loop; end loop; if block_x = NUM_BLOCKS_X - 1 and block_y = NUM_BLOCKS_Y - 1 then pipeline_ready <= true; processing_stage <= 0; -- Reset etapu przetwarzania elsif block_x = NUM_BLOCKS_X - 1 then block_x <= 0; block_y <= block_y + 1; else block_x <= block_x + 1; end if; when 1 => -- Obliczenia gradientów sobel_x_stage <= (to_integer(unsigned(image(block_x * 4 - 1, block_y * 4 - 1))) * sobel_mask_x(0, 0)) + (to_integer(unsigned(image(block_x * 4, block_y * 4 - 1))) * sobel_mask_x(0, 1)) + (to_integer(unsigned(image(block_x * 4 + 1, block_y * 4 - 1))) * sobel_mask_x(0, 2)) + (to_integer(unsigned(image(block_x * 4 - 1, block_y * 4))) * sobel_mask_x(1, 0)) + (to_integer(unsigned(image(block_x * 4 + 1, block_y * 4))) * sobel_mask_x(1, 2)) + (to_integer(unsigned(image(block_x * 4 - 1, block_y * 4 + 1))) * sobel_mask_x(2, 0)) + (to_integer(unsigned(image(block_x * 4, block_y * 4 + 1))) * sobel_mask_x(2, 1)) + (to_integer(unsigned(image(block_x * 4 + 1, block_y * 4 + 1))) * sobel_mask_x(2, 2)); sobel_y_stage <= (to_integer(unsigned(image(block_x * 4 - 1, block_y * 4 - 1))) * sobel_mask_y(0, 0)) + (to_integer(unsigned(image(block_x * 4, block_y * 4 - 1))) * sobel_mask_y(0, 1)) + (to_integer(unsigned(image(block_x * 4 + 1, block_y * 4 - 1))) * sobel_mask_y(0, 2)) + (to_integer(unsigned(image(block_x * 4 - 1, block_y * 4))) * sobel_mask_y(1, 0)) + (to_integer(unsigned(image(block_x * 4 + 1, block_y * 4))) * sobel_mask_y(1, 2)) + (to_integer(unsigned(image(block_x * 4 - 1, block_y * 4 + 1))) * sobel_mask_y(2, 0)) + (to_integer(unsigned(image(block_x * 4, block_y * 4 + 1))) * sobel_mask_y(2, 1)) + (to_integer(unsigned(image(block_x * 4 + 1, block_y * 4 + 1))) * sobel_mask_y(2, 2)); gradient_stage <= abs(sobel_x_stage) + abs(sobel_y_stage); if gradient_stage > 1000 then edge_stage <= '1'; else edge_stage <= '0'; end if; processing_stage <= 2; -- Przejdź do etapu 2 when 2 => -- Wczytywanie wyników do bufora krawędzi edge_buffer(block_x * 4 + 3, block_y * 4 + 3) <= edge_stage; if block_x = NUM_BLOCKS_X - 1 and block_y = NUM_BLOCKS_Y - 1 then pipeline_ready <= false; -- Zakończenie przetwarzania bloku elsif block_x = NUM_BLOCKS_X - 1 then block_x <= 0; block_y <= block_y + 1; else block_x <= block_x + 1; end if; end case; end if; end if; end if; end process; end ParallelPipelinedBehavior; Co sądzicie o wygenerowanym kodzie - wstepnie go przeanalizowałem i na rzaie nie mogę znaleźć błędu. Co sądzicie ogólnie o generacji kodu w róznych językach programowania za pomocą "chatGPT" i ogólnie AI. Tutaj link do dużo potężniejszego narzędzia AI o nazwie kodowej "Gorilla" : https://lablab.ai/tech/gorilla Projekt "Gorilla" można za darmo testować na "Google Clolab". Pozdrawiam -
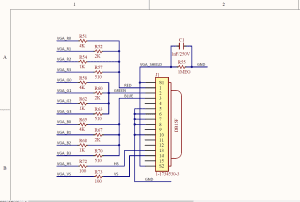
Cześć, dzisiaj wykonałem próbę podłączenia prostej kamery VGA (sensor CMOS) do zestawu FPGA firmy QMTECH z Artix-7 (chip FPGA: XC7A100T-2FGG677i). Tutaj jest link do tego zestawu: https://pl.aliexpress.com/item/4000170042795.html?spm=a2g0o.productlist.0.0.1bbc3a488cWayC&algo_pvid=b8e2d6de-11a7-4045-be1d-dc82c5229b85&algo_expid=b8e2d6de-11a7-4045-be1d-dc82c5229b85-3&btsid=39edaf33-09cc-4522-882b-0168a91a733d&ws_ab_test=searchweb0_0,searchweb201602_4,searchweb201603_55i Zestaw ten kupiłem jakiś czas temu i postanowiłem go użyć w tym projekcie ze względu na dużą ilość zasobów - szczególnie dużą ilość BRAM 4,660Kb (potrzebna na frame-buffer). Pewnie łatwiej i sensowniej byłoby podłączać jakąś kamerę z interfejsem MIPI (i lepszym sensorem), ale nie posiadam żadnego zestawu FPGA, który by miał wbudowany taki interfejs 😉 Jest to moja pierwsza próba podłączenia jakiejkolwiek kamery do zestawu FPGA. Wybrałem tanią kamerę "OV7670" (sensor firmy Omnivision) - tutaj link do sklepu (chińskiego): https://www.banggood.com/Wareshare-OV7670-Camera-Module-CMOS-Acquisition-Board-Adjustable-Focus-300000-Pixel-p-1478355.html?rmmds=search&cur_warehouse=CN Tutaj link do datasheet do tego sensora: https://www.voti.nl/docs/OV7670.pdf Wybrałem projekt ze strony "FPGA4Student" ponieważ z kilku branych pod uwagę wydał mi się najprostszy:był https://www.fpga4student.com/2018/08/basys-3-fpga-ov7670-camera.html Projekt był zrobiny dla zestawu FPGA "Basys 3" z Artixem-7 (XC7A35T-1CPG236C) który posiada tylko 1800 Kb wewnętrznej pamieci BRAM - stąd frame-buffer obsługuje tylko max. rozdzielczość 320x240. Można by go też odpalić na zestawach "Artix-7 35T Arty" lub "Digilent Cmod At-35T" - tutaj linki do tych zestawów: https://kamami.pl/zestawy-uruchomieniowe/560134-artix-7-35t-arty-zestaw-ewaluacyjny-dla-fpga-artix-7.html https://kamami.pl/zestawy-uruchomieniowe/562401-digilent-cmod-a7-35t-modul-uruchomieniowy-z-fpga-artix-7-410-328-35.html Ale wracając do projektu - moja płytka FPGA firmy QMTECH (XC7A100T) nie posiada wyjściowego interfejsu VGA (ma HDMI które wypróbowałem i które działa dobrze), stąd wynikła potrzeba zbudowania go samemu. Wybrałem prosty interfejs (12) rezystorów wzorując się na układzie z zestawu "Basys 3". Tutaj schemat tego interfejsu: Zmontowałem do na płytce prototypowej (potrzebne jest gniazdo VGA 15 pinowe). Tak wygląda cały układ z kamerą, interfejsem VGA (na zielonej płytce) i zestawem FPGA QMTECH. A tu obraz na monitorze (tylko składowa niebieska): Jak widzicie próba nie zakończyła się pełnym sukcesem obraz jest o rozdzielczości 320x240 pikseli (i tak miało być) natomiast jest widoczna na ekranie tylko składowa niebieska.Podejrzewam, że błąd jest na zielonej płytce z interfejsem VGA - bo była ona dzisiaj "na szybko" polutowana a nie była najpierw przetestowana (może pomyliłem się przy gnieździe VGA). Zamieszczam tu pełen projekt dla Vivado 2018.3. Plik constraints dla mojej płytki QMETCH, ale na oryginalnej stronie projektu mo\zna pobrać pełen projekt dla "Basys 3". basys3_ov7670_v1.zip W najbliższym czasie zamierzam usunąć błędy z interfejsu VGA oraz zwiększyć pojemność frame-buffer'a do pełnej rozdzielczości VGA (na mojej płytce powinno wystarczyć pamieci BRAM w układzie FPGA). Zamieszczam projekt, bo może ktoś będzie także chciał spróbować podłączyć taki model kamery do układu FPGA. Zachęcam wszystkich do własnych prób z układami FPGA, bo w dziale "Układy programowalne" na Forbocie ostatnio bardzo mało się dzieje. Pozdrawiam 🙂


-
W ramach pewnego projektu muszę obsłużyć komunikację za pomocą interfejsu LVDS w układzie programowalnym FPGA (lub w zasadzie, w tej chwili, SoC). Interesuje mnie zarówno nadajnik, jak również odbiornik. Szukam materiałów na ten temat w internecie i w zasadzie jedyne co znalazłem to odpowiednie skonfigurowanie pinów i użycie prymitywów (np. IBUFDS - dla Xilinxa) w kodzie VHDL (tego języka używam). Czy jest jakaś (w miarę prosta) możliwość zastąpienia tych prymitywów własnym kodem? Nie mam pomysłu na napisanie takiego elementu, niewprowadzającego zbędnych opóźnień. Zależy mi na zapewnieniu możliwie jak największej „przenoszalności" kodu. Czy jest możliwość sprawdzenia, co tak naprawdę znajduje się w tych prymitywach (chciałbym zobaczyć, co „siedzi" w środku)? Czy może jest to po prostu fizyczny element, „zaszyty" wewnątrz FPGA? Czy jeżeli opiszę własny komponent, mający dwa wejścia (sygnały różnicowe zanegowany i nie) i jedno wyjście (które będzie po prostu podłączone do wejścia niezanegowanego lub będzie działać według załączonej tabeli zaczerpniętej z dokumentacji Xilinxa), to narzędzie do syntezy „domyśli się", że trzeba wstawić w to miejsce wejściowy bufor różnicowy? Czy nie będzie problemu z przeniesieniem projektu na inny układ (innego producenta)? Przepraszam za poziom pytań, ale pierwszy raz będę korzystał z transmisji różnicowej i nie wszystko jest dla mnie jasne. Ponadto, nie mam dużego doświadczenia z układami programowalnymi.

-
Witam, Chciałbym zaprezentować swojego pierwszego robota "Robot FPGA v02". Opisywana konstrukcja to dwukołowy robot napędzany silnikami DC bezpośrednio połączonymi z kołami. Podwozie podpiera się na ruchomej kulce znajdującej się z tyłu. Platforma mobilna została wykonana z plastiku łączonego klejem lub śrubami. Silniki DC sterowane są metodą PWM i podłączone są do wyjść podwójnego mostka H bazującego na układzie L298. Zasilanie robota to osiem akumulatorów typu AA. Oprogramowanie zostało napisane w języku VHDL i wykonuje się na układzie FPGA Altera Cyclon II. Platforma FPGA to płytka rozwojowa Terasic DE1, zasilana jest przez przetwornicę impulsową. Robot posiada zapisaną na stałe sekwencję ruchów. W kodzie są to dwie listy, gdzie pierwsza lista zawiera nazwę ruchu, druga lista zawiera czas przez jaki ma się on wykonywać. Lista komend ruchu: IDLE, FORWARD, BACKWARD, TURN_LEFT, TURN_RIGHT, ROTATE_L, ROTATE_R. Dane techniczne: Masa robota: 965g Wymiary: szerokość, długość, wysokość : 190mm/200mm/105mm Maksymalna prędkość: 0.295 m/s (1.062 km/h) Maksymalny kąt podjazdu: 30 stopni Prześwit: 10mm Promień koła: 30mm Napięcie zasilania płytki FPGA Terasic DE1: 7,5V Parametry wyjść płytki DE1: 3.3V/25mA Napięcie zasilania silników DC: od 8,8V do 10,4V Rodzaj zasilania: 8 akumulatorów AA (NiMH) Częstotliwość PWM: 2000Hz Robot jest podstawową platformą, która posiada miejsce i zasoby pozwalające na rozbudowę i ulepszenia. Dla zainteresowanych, szczegóły opis projektu znajduje się na stronie: Link do dokumentacji robota