radek04
-
Zawartość
219 -
Rejestracja
-
Ostatnio
Osiągnięcia użytkownika radek04
")





-
STM32 Zapis danych uint8_t do tablicy uint32_t
radek04 odpisał w temacie użytkownika radek04 • Programowanie
No to chyba mamy identycznie z tymi światecznymi motywami 😉 Ja zaczynałem od "Symfonii C++" i teraz się zastanawiam, czy warto kupić książkę do ANSI C, czy to niewiele zmieni. W sumie to C używam jedynie do STM32... -
STM32 Zapis danych uint8_t do tablicy uint32_t
radek04 odpisał w temacie użytkownika radek04 • Programowanie
@ethanak, wielkie dzięki. Działa mi to teraz dokładnie tak, jak chciałem. A nawet trochę lepiej 😉- 13 odpowiedzi
-
- 1
-

-
- rzutowanie
- uint8
- (i 2 więcej)
-
STM32 Zapis danych uint8_t do tablicy uint32_t
radek04 odpisał w temacie użytkownika radek04 • Programowanie
Unia, oczywiste. Tak to jest, gdy się korzysta tylko z najprostszych mechanizmów, nie mając większego pojęcia o programowaniu. Co do grzyba - fakt, wygląda to dziwnie. Temat jest bardziej złożony. W różnych fragmentach przedstawiałem go w innych tematach na forum. Czasami bez żadnej odpowiedzi. W skrócie - tablica ta służy do akwizycji danych z różnych czujników. Dopóki zapisuję je w tablicy, pomiary są robione ze stałym okresem próbkowania. W momencie zapisu na kartę ciągłość pomiaru zostaje zaburzona. Stąd potrzeba jak największej tablicy, by przez jak najdłuższy czas pobierać spójne dane. Próbowałem różnych sposobów np. Z 2 buforami używanymi na zmianę, z DMA i in., ale zawsze podczas zapisu na kartę następuje krótka przerwa w akwizycji danych. Pewnie da się to jakoś lepiej zrobić, ale z moimi umiejętnościami programistycznymi się nie powiodło. -
Cześć, z uwagi na ograniczoną ilość pamięci w STM32H7, w celu pełnego wykorzystania jej zasobów, chciałbym współdzielić jeden duży bufor do dwóch zadań (gdy pierwsze zadanie się skończy, zaczyna się drugie, więc dane "nie kłócą się ze sobą"). Normalnie korzystam z tablic: uint32_t tab1[119256] w jednym programie oraz uint8_t tab2[278528] w drugim ( (round_No=4096)*(liczba_rejestrów=68) ). Przyszedł czas połączyć programy i okazało się, że pamięci brakuje. Stąd pomysł, by wykorzystać jeden bufor (tablicę) do obu celów. Mam jednak problem z poprawnym zapisem danych. Próbowałem bardzo różnych kombinacji, może nie będę ich wymieniał, by nie narzucać (złych) pomysłów. Proszę o pomoc, jak poprawnie skonstruować zapis do tablicy, a następnie zapis tablicy na kartę. Dobrze byłoby, gdybym w pełni wykorzystał tab1 i mógł użyć 2 razy więcej komórek 8-bitowych niż jest komórek 32-bitowych, ale jeśli zostanie mi do dyspozycji owe 119256, to też da radę. Poniżej krytyczne fragmenty programu, czyli akwizycja danych do tablicy oraz ich zapis na kartę pamięci. HAL_I2C_Mem_Read_DMA(&hi2c1, MPU9250_ACC_ADDRESS_A, MPU9250_ACCEL_XOUT_H, 1, &tab[round_No*68 + 0*14], 14); //14 registers measurement HAL_I2C_Mem_Read_DMA(&hi2c2, MPU9250_ACC_ADDRESS_B, MPU9250_ACCEL_XOUT_H, 1, &tab[round_No*68 + 1*14], 14); //14 registers measurement HAL_I2C_Mem_Read_DMA(&hi2c3, MPU9250_ACC_ADDRESS_C, MPU9250_ACCEL_XOUT_H, 1, &tab[round_No*68 + 2*14], 14); //14 registers measurement HAL_I2C_Mem_Read_IT (&hi2c4, MPU9250_ACC_ADDRESS_D, MPU9250_ACCEL_XOUT_H, 1, &tab[round_No*68 + 3*14], 14); //14 registers measurement HAL_I2C_Mem_Read_DMA(&hi2c1, BMP280_ADDRESS_A, BMP280_REG_BAR_MSB, 1, &tab[round_No*68 + 4*14+0*3], 3); //3 registers measurement HAL_I2C_Mem_Read_DMA(&hi2c2, BMP280_ADDRESS_B, BMP280_REG_BAR_MSB, 1, &tab[round_No*68 + 4*14+1*3], 3); //3 registers measurement HAL_I2C_Mem_Read_DMA(&hi2c3, BMP280_ADDRESS_C, BMP280_REG_BAR_MSB, 1, &tab[round_No*68 + 4*14+2*3], 3); //3 registers measurement HAL_I2C_Mem_Read_IT (&hi2c4, BMP280_ADDRESS_D, BMP280_REG_BAR_MSB, 1, &tab[round_No*68 + 4*14+3*3], 3); //3 registers measurement f_write(&fil, readings_from_registers, sizeof(tab), &numread); W tej drugiej części (BMP280) dane pobieram z 3 rejestrów 8-bitowych. Ponieważ może być to kłopotliwe, mogę ograniczyć się do 2 lub rozszerzyć do 4, w którym jeden będzie zawsze zerami. Każda konstruktywna uwaga będzie na dla mnie cenna.
-
I2C - sprawdzenie czy interfejs zakończył poprzedni pomiar
radek04 odpisał w temacie użytkownika radek04 • Programowanie
Dane pobieram 500 razy na sekundę i tak szybko też (w przerwaniu timera) odczytuję je. Dane wyglądają dobrze i za każdym razem delikatnie inne, więc zdaje się, że działa to dobrze. Roboczo przyjmuję, że odczytuję nowe dane po tym, jak się zmieniły i zanim nastąpi kolejna zmiana. W instrukcji BMP280 jest informacja, że jeśli odczyt wykonywany jest seryjnie po kolejnych rejestrach, to dane są zawsze spójne. W MPU9250 podobnej informacji nie znalazłem i przyznaję, że nie sprawdzam tego. Nie bardzo nawet umiem takie rzeczy robić. -
I2C - sprawdzenie czy interfejs zakończył poprzedni pomiar
radek04 odpisał w temacie użytkownika radek04 • Programowanie
Wybaczcie moją niefrasobliwość. Okazało się,że już wcześniej to robiłem funkcją while(HAL_I2C_GetState(&hi2c1) != HAL_I2C_STATE_READY){} Tylko teraz nasuwa mi się pytanie, czy lepiej sprawdzać każdą linię I2C osobno while(HAL_I2C_GetState(&hi2c1) != HAL_I2C_STATE_READY){} HAL_I2C_Mem_Read_DMA(&hi2c1, BMP280_ADDRESS_A, BMP280_REG_BAR_MSB, 1, BMP280_Data_A, 3); while(HAL_I2C_GetState(&hi2c2) != HAL_I2C_STATE_READY){} HAL_I2C_Mem_Read_DMA(&hi2c2, BMP280_ADDRESS_B, BMP280_REG_BAR_MSB, 1, BMP280_Data_B, 3); while(HAL_I2C_GetState(&hi2c3) != HAL_I2C_STATE_READY){} HAL_I2C_Mem_Read_DMA(&hi2c3, BMP280_ADDRESS_C, BMP280_REG_BAR_MSB, 1, BMP280_Data_C, 3); while(HAL_I2C_GetState(&hi2c4) != HAL_I2C_STATE_READY){} HAL_I2C_Mem_Read_IT (&hi2c4, BMP280_ADDRESS_D, BMP280_REG_BAR_MSB, 1, BMP280_Data_D, 3); while(HAL_I2C_GetState(&hi2c1) != HAL_I2C_STATE_READY){} HAL_I2C_Mem_Read_DMA(&hi2c1, MPU9250_ACC_ADDRESS_A, MPU9250_ACCEL_XOUT_H, 1, MPU9250_Data_A, 14); while(HAL_I2C_GetState(&hi2c2) != HAL_I2C_STATE_READY){} HAL_I2C_Mem_Read_DMA(&hi2c2, MPU9250_ACC_ADDRESS_B, MPU9250_ACCEL_XOUT_H, 1, MPU9250_Data_B, 14); while(HAL_I2C_GetState(&hi2c3) != HAL_I2C_STATE_READY){} HAL_I2C_Mem_Read_DMA(&hi2c3, MPU9250_ACC_ADDRESS_C, MPU9250_ACCEL_XOUT_H, 1, MPU9250_Data_C, 14); while(HAL_I2C_GetState(&hi2c4) != HAL_I2C_STATE_READY){} HAL_I2C_Mem_Read_IT (&hi2c4, MPU9250_ACC_ADDRESS_D, MPU9250_ACCEL_XOUT_H, 1, MPU9250_Data_D, 14); czy wystarczy wszystkie jednocześnie? while( HAL_I2C_GetState(&hi2c1) != HAL_I2C_STATE_READY || HAL_I2C_GetState(&hi2c2) != HAL_I2C_STATE_READY || HAL_I2C_GetState(&hi2c3) != HAL_I2C_STATE_READY || HAL_I2C_GetState(&hi2c4) != HAL_I2C_STATE_READY){} HAL_I2C_Mem_Read_DMA(&hi2c1, BMP280_ADDRESS_A, BMP280_REG_BAR_MSB, 1, BMP280_Data_A, 3); HAL_I2C_Mem_Read_DMA(&hi2c2, BMP280_ADDRESS_B, BMP280_REG_BAR_MSB, 1, BMP280_Data_B, 3); HAL_I2C_Mem_Read_DMA(&hi2c3, BMP280_ADDRESS_C, BMP280_REG_BAR_MSB, 1, BMP280_Data_C, 3); HAL_I2C_Mem_Read_IT (&hi2c4, BMP280_ADDRESS_D, BMP280_REG_BAR_MSB, 1, BMP280_Data_D, 3); while( HAL_I2C_GetState(&hi2c1) != HAL_I2C_STATE_READY || HAL_I2C_GetState(&hi2c2) != HAL_I2C_STATE_READY || HAL_I2C_GetState(&hi2c3) != HAL_I2C_STATE_READY || HAL_I2C_GetState(&hi2c4) != HAL_I2C_STATE_READY){} HAL_I2C_Mem_Read_DMA(&hi2c1, MPU9250_ACC_ADDRESS_A, MPU9250_ACCEL_XOUT_H, 1, MPU9250_Data_A, 14); HAL_I2C_Mem_Read_DMA(&hi2c2, MPU9250_ACC_ADDRESS_B, MPU9250_ACCEL_XOUT_H, 1, MPU9250_Data_B, 14); HAL_I2C_Mem_Read_DMA(&hi2c3, MPU9250_ACC_ADDRESS_C, MPU9250_ACCEL_XOUT_H, 1, MPU9250_Data_C, 14); HAL_I2C_Mem_Read_IT (&hi2c4, MPU9250_ACC_ADDRESS_D, MPU9250_ACCEL_XOUT_H, 1, MPU9250_Data_D, 14); Chodzi mi o to, który sposób będzie szybszy, jeśli przy trybach DMA i IT to w ogóle ma jakieś znaczenie. -
I2C - sprawdzenie czy interfejs zakończył poprzedni pomiar
radek04 opublikował temat w Programowanie
Cześć, używam w projekcie 4 modułów GY-91. Odczytuję z nich 500 razy na sekundę wartości z akcelerometru, żyroskopu i barometru. O ile osobno IMU i BAR działają dobrze, o tyle mam problem z "symultanicznym" odczytem wszystkich danych. Korzystam z 4 linii I2C (każdy moduł podłączony do innej) oraz odczytu w trybach DMA oraz IT. Problem w tym, że zarówno IMU (akcelerometr i żyroskop), jak i barometr korzystają ze wspólnego interfejsu I2C. Poprawnie mogę odczytać tylko te dane, które w programie są jako pierwsze (reszta zostaje zerami). Podejrzewam, że kolejny pomiar próbuję zrobić, zanim poprzedni się zakończył. Jak sprawdzić, czy operacja HAL_I2C_Mem_Read_DMA() została już zakończona i mogę wykonać kolejny pomiar po tej samej linii I2C? Jest jakaś flaga do tego? Na razie roboczo wstawiłem opóźnienie, ale to rozwiązanie nie do końca mnie zadowala, ponieważ ważna dla mnie jest każda mikrosekuda. Poza tym to niezbyt eleganckie rozwiązanie. Używam STM32H743ZII, STM32CubeIDE. HAL_I2C_Mem_Read_DMA(&hi2c1, BMP280_ADDRESS_A, BMP280_REG_BAR_MSB, 1, BMP280_Data_A, 3); // 3 registers (MSB, LSB, XLSB) HAL_I2C_Mem_Read_DMA(&hi2c2, BMP280_ADDRESS_B, BMP280_REG_BAR_MSB, 1, BMP280_Data_B, 3); // 3 registers (MSB, LSB, XLSB) HAL_I2C_Mem_Read_DMA(&hi2c3, BMP280_ADDRESS_C, BMP280_REG_BAR_MSB, 1, BMP280_Data_C, 3); // 3 registers (MSB, LSB, XLSB) HAL_I2C_Mem_Read_IT (&hi2c4, BMP280_ADDRESS_D, BMP280_REG_BAR_MSB, 1, BMP280_Data_D, 3); // 3 registers (MSB, LSB, XLSB) Hal_Delay(1); HAL_I2C_Mem_Read_DMA(&hi2c1, MPU9250_ACC_ADDRESS_A, MPU9250_ACCEL_XOUT_H, 1, MPU9250_Data_A, 14); //14 registers measurement HAL_I2C_Mem_Read_DMA(&hi2c2, MPU9250_ACC_ADDRESS_B, MPU9250_ACCEL_XOUT_H, 1, MPU9250_Data_B, 14); //14 registers measurement HAL_I2C_Mem_Read_DMA(&hi2c3, MPU9250_ACC_ADDRESS_C, MPU9250_ACCEL_XOUT_H, 1, MPU9250_Data_C, 14); //14 registers measurement HAL_I2C_Mem_Read_IT (&hi2c4, MPU9250_ACC_ADDRESS_D, MPU9250_ACCEL_XOUT_H, 1, MPU9250_Data_D, 14); //14 registers measurement -
Bufor cykliczy - nadpisywanie 1 elementu, odczyt całości
radek04 odpisał w temacie użytkownika radek04 • Programowanie
Funkcja dittt() to uogólniona postać szybkiej transformacji Fouriera. Jako dane wejściowe przyjmuje liczby zespolone: indeks parzysty - część rzeczywista, indeks nieparzysty - część urojona. W moim przypadku są tylko liczby rzeczywiste, dlatego "ręcznie" muszę dodać część urojoną, stąd rozszerzony 2x bufor. Masz rację. Dlatego - dopiero po napisaniu mojego posta - pomyślałem o tym, by ta główna tablica AaX o rozmiarze TRSIZ była buforem cyklicznym, natomiast wartości w tablicy adcc_AaX o rozmiarze 2*TRSIZ "układać" w taki sposób, by pod indeksem nr 0 znalazł się zawsze odpowiedni w danym momencie element z bufora AaX. I chyba właśnie coś takiego zaproponowałeś. Zdaje się, że właśnie o to mi chodziło. Dzięki. -
Bufor cykliczy - nadpisywanie 1 elementu, odczyt całości
radek04 odpisał w temacie użytkownika radek04 • Programowanie
Kurczę, chyba nie będzie to tak proste, jak mi się wydawało. Ale może znów coś doradzicie. Chodzi o to, że w jednym momencie owo "przetwarzanie danych" to nie trywialna operacja matematyczna, a szybka transformata Fouriera (FFT). Korzystam z gotowej funkcji i mam pewne wątpliwości, w które miejsca dokładnie dodawać operację modulo z użyciem indeksu, a w które nie. Zastanawiam się, czy przed wywołaniem funkcji FFT o nazwie dittt() można użyć tej sztuczki z modulo, czy jednak trzeba ingerować w samą funkcję dittt(). Żeby nie zmieniać oznaczeń w kodzie, podaję moje odpowiedniki wcześniej wymienionych zmiennych: BUF_SIZE - TRSIZ index - iteration_TRSIZ Program wykonuje kilka operacji po drodze, ale w najważniejszym momencie mój bufor (tak naprawdę mam 24 podobne bufory, ale będę pisał o jednym) jest rozszerzany dwukrotnie i w co drugie miejsce wpisywane są zera (wartości urojone - wymagania użytej funkcji FFT). for (int i = TRSIZ-1; i >= 0; i--) { adcc_AaX[2*i] = AaX[i]; //parzyste indeksy - real adcc_AaX[2*i+1] = 0; //nieparzyste indeksy - imagine //tutaj pozostałe bufory } (Wiele lat temu pierwszy raz korzystałem z tej funkcji FFT i w sumie dziś już nie wiem, dlaczego indeks w pętli jest dekrementowany, a nie inkrementowany. Ale zdaje się, że nie ma to znaczenia) Następnie ten rozszerzony bufor poddawany jest przetwarzaniu FFT: for (int i = 0; i < liczba_sensorow; i++) { if (i==0) dittt(adcc_AaX); //tutaj pozostałe bufory } Poniżej gwóźdź programu, czyli realizacja FFT: void dittt(float data1[2*TRSIZ]) //oblicza FFT { skok = fs / TRSIZ; float wtemp, wr, wpr, wpi, wi, theta; float tempr, tempi; int N = TRSIZ; int i = 0, j = 0, n = 0, k = 0, m = 0, isign = -1, istep, mmax; float *data; data = &data1[0] - 1; //data = &data1[(0+iteration_TRSIZ)%TRSIZ] - 1; //Tutaj moja zmiana - czy dobrze? Czy raczej musi być już 2*TRSIZ zamiast TRSIZ? n = N * 2; j = 1; //do the bit-reversal for (i = 1; i < n; i += 2) { if (j > i) { SWAP(data[j], data[i]); //czy tutaj modulo? SWAP(data[j + 1], data[i + 1]); //czy tutaj modulo? } m = n >> 1; while (m >= 2 && j > m) { j -= m; m >>= 1; } j += m; } //calculate the FFT mmax = 2; while (n > mmax) { istep = mmax << 1; theta = isign * (6.28318530717959 / mmax); wtemp = sin(0.5 * theta); wpr = -2.0 * wtemp * wtemp; wpi = sin(theta); wr = 1.0; wi = 0.0; for (m = 1; m < mmax; m += 2) { for (i = m; i <= n; i += istep) { j = i + mmax; tempr = wr * data[j] - wi * data[j + 1]; //czy tutaj modulo? tempi = wr * data[j + 1] + wi * data[j]; //czy tutaj modulo? data[j] = data[i] - tempr; //czy tutaj modulo? data[j + 1] = data[i + 1] - tempi; //czy tutaj modulo? data[i] = data[i] + tempr; //czy tutaj modulo? data[i + 1] = data[i + 1] + tempi; //czy tutaj modulo? } wtemp = wr; wr += wtemp * wpr - wi * wpi; wi += wtemp * wpi + wi * wpr; } mmax = istep; } for (k = 0; k < N; k += 2) { m = k / 2; if (k == 0) { fx[m] = 0.0; amplituda[m] = 0; } //zerowanie w indeksie [0] else { modul = sqrt(pow(data[k + 1], 2) + pow(data[k + 2], 2)); //czy tutaj modulo? fx[m] = fx[m - 1] + skok; amplituda[m] = modul * 2 / TRSIZ; } featuresSTM[wykonania_dittt*TRSIZ/2+m] = amplituda[m]; } wykonania_dittt++; } W komentarzach zaznaczyłem miejsca, gdzie wg mnie powinny być zmiany. Proszę o sprawdzenie mojego pomysłu. I rozumiem, że w tej funkcji korzystać muszę już z rozmiaru bufora równego 2*TRSIZ, prawda? Mimo że rzeczywiste (niezerowe) wartości występują tylko w liczbie TRSIZ. Chyba że zaproponujecie jakiś lepszy sposób użycia bufora cyklicznego bez ingerencji w funkcję dittt(), która nie jest mojego autorstwa (coś tam bardzo delikatnie dorobiłem na swoje potrzeby). Może da radę w miejscu, gdzie rozszerzam bufor, poukładać dane w odpowiedniej kolejności? -
Bufor cykliczy - nadpisywanie 1 elementu, odczyt całości
radek04 odpisał w temacie użytkownika radek04 • Programowanie
Korzystam z STM32 i piszę w C. No tak, modulo powinno wystarczyć. Myślałem o tym, by od razu odczytać wiele komórek bez jorzystania z petli, ale z pętlą for też powinno być dobrze. -
Cześć, problem mam chyba dość prosty, ale przy moich umiejetnościach robi się trudny 🙂 Potrzebuję bufor cykliczny, który będę zapełniał odczytami z czujnika w równych odstępach czasu. W trakcie działania programu chcę najstarszą wartość nadpisać nową, a nastepnie odczytać i przetworzyć cały bufor. Np. dla 8 elementów (indeksy od 0 do 7) i kolejnej iteracji pętli, pod indeks nr 4 zapisuję nowe dane, a następnie odczytuję cały bufor w kolejnosci: 5,6,7,0,1,2,3,4. O ile odczytanie pojedynczej komórki z takiego bufora jest problemem często poruszanym, o tyle mam kłopot ze złożeniem w chronologiczną tablicę całego bufora. Czy za każdym razem muszę podawać adres każdej z 8 komórek bufora, czy da radę odczytać wszystkie 8 (w odpowiedniej kolejności) jednym poleceniem?
-
Typy danych i rozmiar buforów w pdm2pcm - akwizycja dźwięku
radek04 opublikował temat w Mikrokontrolery
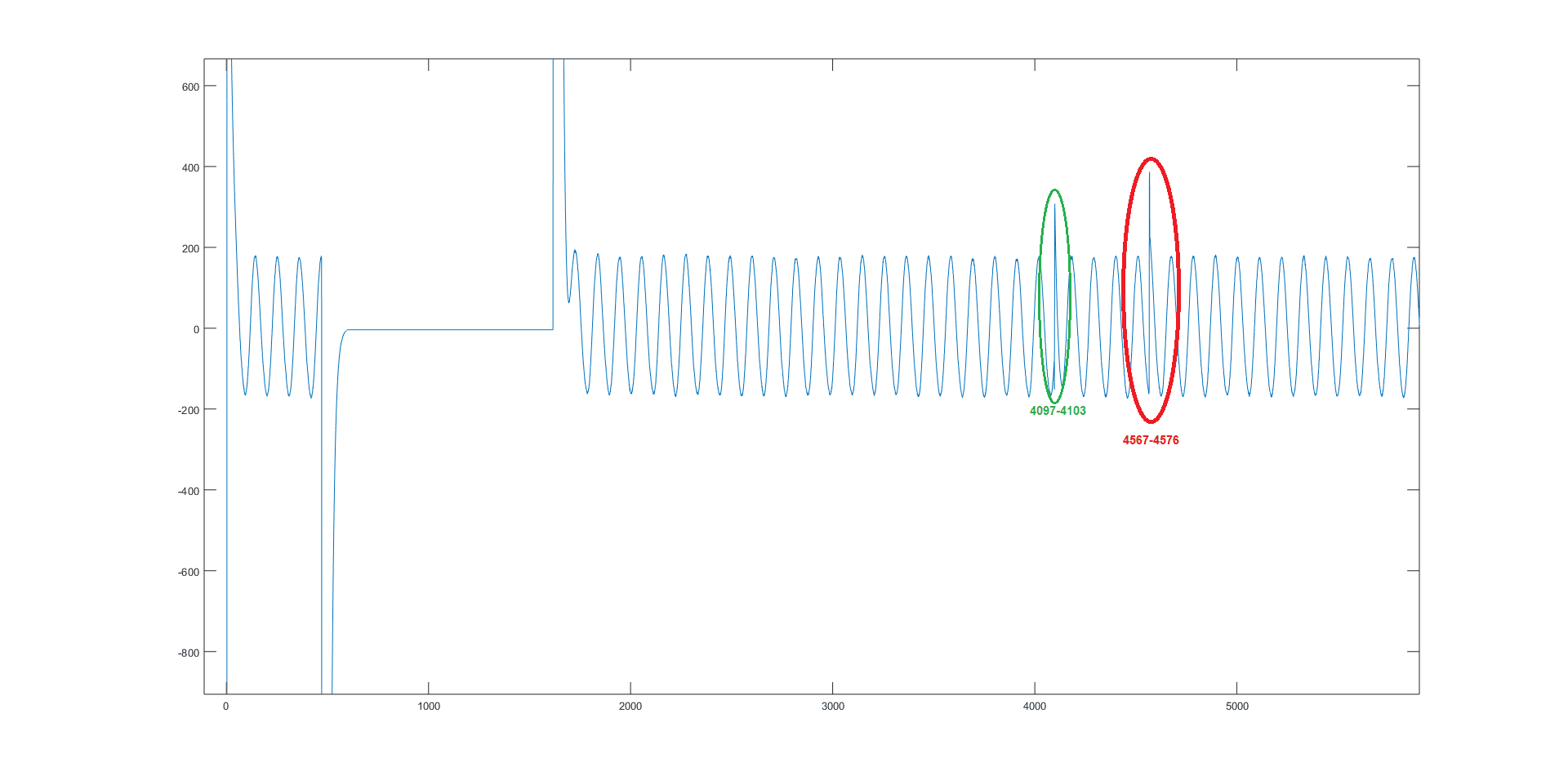
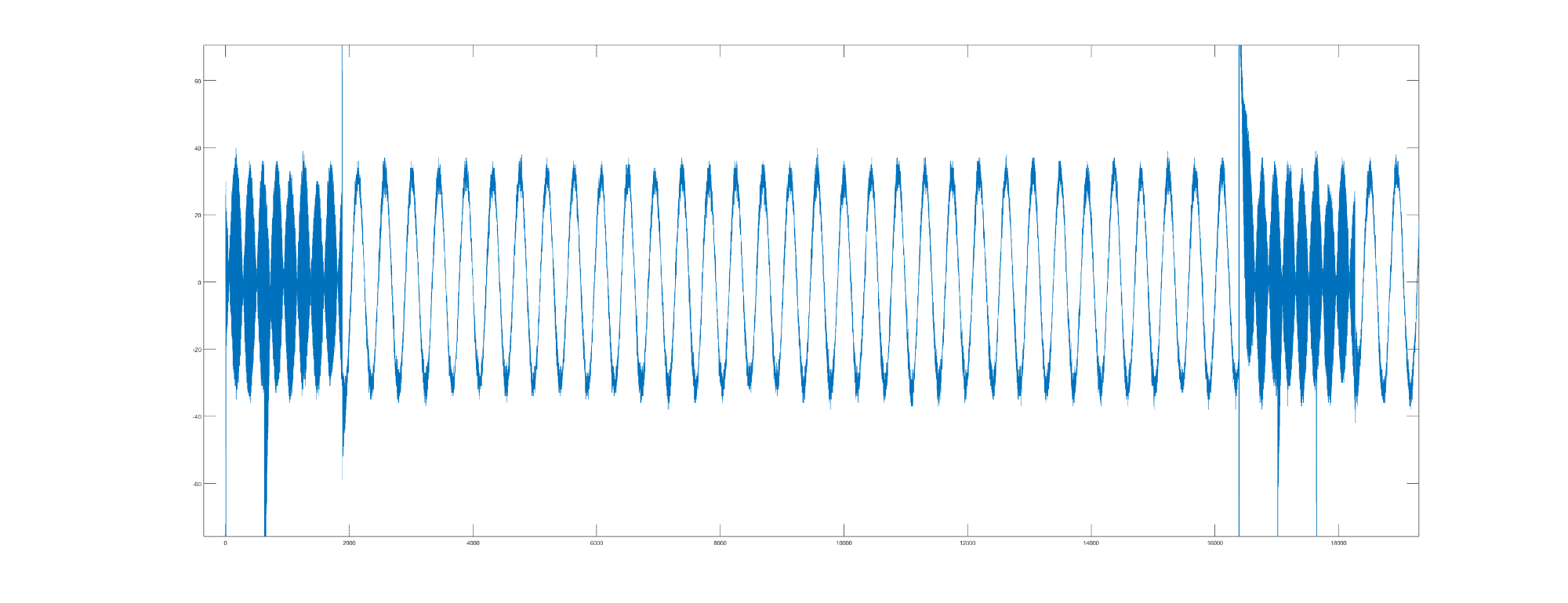
Cześć, przeprowadzam akwizycję dźwięku z 4 mikrofonów MP34DT01-M przy użyciu interfejsu SAI oraz biblioteki pdm2pcm na STM32H743. 1. Moje pierwsze pytanie dotyczy typów zmiennych użytych w buforach PDM i PCM. Dane z 4 mikrofonów zapisuję w 32-bitowych slotach (po 8 bitów na mikrofon) w każdej ramce. Obecnie wygląda to u mnie tak: #define PDM_buffer_size 4096*4*6 //szóstka dobrana eksperymentalnie #define PCM_buffer_size 4096*4 // równy output_samples_number uint32_t PDM_buffer[PDM_buffer_size]; //bufor wejściowy PDM uint16_t PCM_buffer[PCM_buffer_size]; //bufor wyjściowy PCM HAL_SAI_Receive_DMA(&hsai_BlockA1, (uint8_t*)PDM_buffer, PDM_buffer_size); //rozpoczęcie akwizycji PDM_Filter(&(((uint8_t*)PDM_buffer)[0]), &(((uint16_t*)PCM_buffer)[0]), &PDM1_filter_handler); //konwersja PDM na PCM mikrofon A PDM_Filter(&(((uint8_t*)PDM_buffer)[1]), &(((uint16_t*)PCM_buffer)[1]), &PDM2_filter_handler); //konwersja PDM na PCM mikrofon B PDM_Filter(&(((uint8_t*)PDM_buffer)[2]), &(((uint16_t*)PCM_buffer)[2]), &PDM3_filter_handler); //konwersja PDM na PCM mikrofon C PDM_Filter(&(((uint8_t*)PDM_buffer)[3]), &(((uint16_t*)PCM_buffer)[3]), &PDM4_filter_handler); //konwersja PDM na PCM mikrofon D Jednak deklaracja HAL_SAI_Receive_DMA wygląda następująco: HAL_StatusTypeDef HAL_SAI_Receive_DMA(SAI_HandleTypeDef *hsai, uint8_t *pData, uint16_t Size) Z jednej strony wskaźnik jest 8-bitowy, a rozmiar bufora 16-bitowy, a mój jest 32-bitowy. Proszę o info, czy mam to dobrze. 2. Druga kwestia dotyczy rozmiaru użytych buforów. O ile PCM_buffer jest dość oczywisty i równy wartości output_samples_number (the number of samples by request) pomnożonej przez 4 mikrofony, o tyle z PDM_buffer mam już kłopot. Wartość dobrałem eksperymentalnie, aż zadziałało, natomiast nie mam pojęcia, dlaczego z tą szóstką już działa, a np. z czwórką nie. Korzystam z decimation ratio równym 64. 3. Zgodnie z RM0433 str. 2254 dwie pierwsze ramki (zielona pętla) są nieprawidłowe. I o ile dla mikrofonu A mi się to sprawdza, o tyle dla pozostałych 3 mikrofonów pojawia się jeszcze jeden moment, w którym wartości są nieprawidłowe (na czerwono w załączonym pliku). (Ten cały pierwszy przebieg 1-4096 pomijam w zapisie, więc to nie jest dla mnie problem, choć nie wiem, dlaczego tak dziwnie wygląda.) Dodatkowo załączam wykres z wszystkich 4 mikrofonów, który w zasadzie powinien być jedną (pogrubioną) sinusoidą. Na tym wykresie kolejne wartości to odpowiednio próbki: A1,B1,C1,D1, A2,B2,C2,D2, A3,B3,C3,D3... Widać, że na początku każdego cyklu akwizycji (4*4096 próbek) następuje jakby przesunięcie w fazie. Na pierwszym wykresie zresztą też te nieprawidłowe wartości w czerwonej pętli wyglądają jak ucięta sinusoida i rozpoczęcie kolejnej w niewłaściwym miejscu. Proszę o wszelkie pomysły i podpowiedzi, co mogę mieć źle, jaka jest przyczyna błędu lub jak jej zapobiec. Na razie nie załączam kodu, ale jest on dość prosty i w czasie pojedynczego cyklu (4*4096) nie dzieje się nic poza akwizycją i konwersją.
-
STM32H7 Problem z UART po włączeniu pakietu AI
radek04 odpisał w temacie użytkownika radek04 • Mikrokontrolery
Nikt wcześniej nie spotkał się z podobnym problemem? Jakiekolwiek pomysły, o co może chodzić? Na płytce Nucleo dokładnie taki sam efekt. Testowałem na dwóch różnych komputerach. -
Cześć, napotkałem dziś dziwny problem. Po dodaniu do projektu STM32H743IIT6 pakietu X-CUBE-AI przestała działać komunikacja USART. Mam na PCB wyprowadzone USART2 oraz USART3 i żaden z nich nie działa. Zdaje się, że pozostała część programu działa, ale dokładnie tego nie sprawdzałem, jedynie miganie diod. Sprawdzałem wersje 7.3 oaz 8.0 pakietu AI. Najdziwniejsze jest to, że już samo zaznaczenie Core w Select Components (STM32CubeIDE) powoduje problemy. Późniejsze odznaczenie tego nie przywraca działania. Problem nie tkwi w pliku main.c. Przywrócenie pliku sprzed zmian nic nie daje. Komunikacja po USART realizowana jest poprzez programator z Nucleo F1. Wcześniej korzystałem z pakietu AI razem z USART na rdzeniu F7 i nie było problemów. Czy macie jakieś pomysły, gdzie szukać problemu?
-
Jeśli zrobisz w prostokącie 100x100, nikt się nie powinien się czepiać, ile różnych układów tam masz. Zresztą komu chciałoby się to sprawdzać...